Om als samenwerkingsverband de FAIR-methode te gebruiken om gegevens uit te wisselen, zijn vooral de individuele organisaties aan zet. Zij zijn ‘baas over eigen data’ en zorgen ervoor dat hun gegevens voldoen aan de FAIR-principes, waardoor ze op te vragen zijn door de samenwerkingspartners.
Het concept
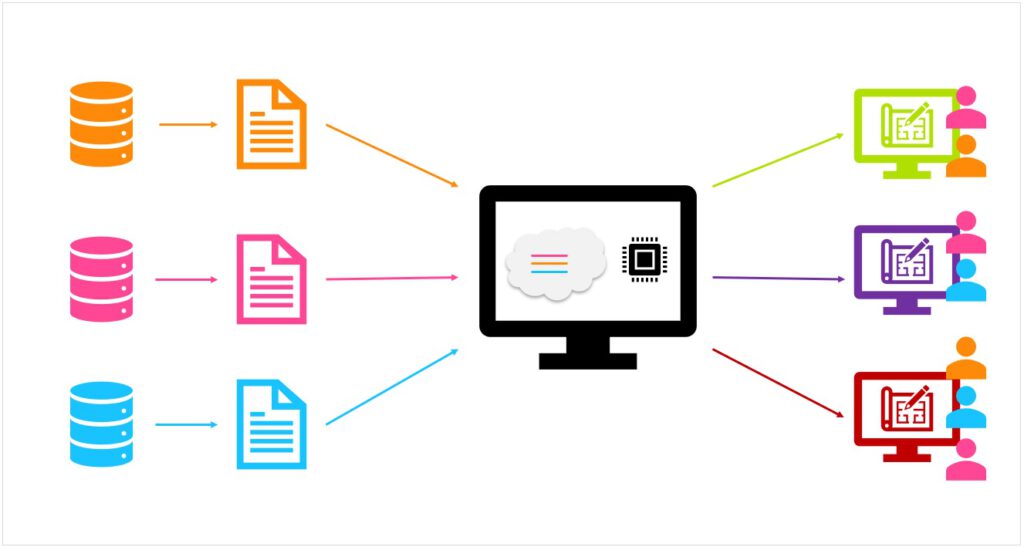
Via het ‘FAIRification’-proces (zie verderop) worden de ruwe datasets omgevormd tot FAIR-datasets. Dit houdt onder meer in dat de datasets beschreven worden met metadata. Dankzij die metadata kunnen de bronnen online gevonden worden, bijvoorbeeld via een repository (verzamelplaats). Ook deze repository moet weer voldoen aan de FAIR-principes. Een samenwerkingsverband kan gebruikmaken van een reeds bestaande repository, of er zelf eentje opzetten. Dit laatste kan bijvoorbeeld door een FAIR Datapoint te implementeren, zie ook verderop. Samenwerkingsverbanden kunnen vervolgens via de repository de data binnenhalen die zij nodig hebben. Het maakt niet uit welke software ze gebruiken; dit kan bijvoorbeeld QGIS zijn of een ander programma om verschillende datasets ‘op elkaar te leggen’.
FAIRification
Door middel van ‘FAIRification’ zorgt een bronhouder ervoor dat zijn dataset voldoet aan de FAIR-principes en zodoende volgens dat concept ontsloten kan worden. Het proces omvat zeven stappen:
- Data verzamelen/bepalen: welke gegevens moeten FAIR worden?
- Data analyseren: waar gaan de gegevens over, hoe zijn de gegevens gestructureerd, etc.? Deze analyse is nodig voor de volgende stap.
- Definiëren van een semantisch
In de taalkunde is semantiek (of betekenisleer) de studie van de betekenis van woorden en van hogere eenheden zoals woordgroepen en zinnen. Een semantische discussie gaat bijvoorbeeld over de vraag wat het woord ‘iedereen’ precies betekent. En het semantische verschil tussen de ene ‘bank’ en de andere ‘bank’ is dat de eerste een zitmeubel is en het tweede een financieel instituut.
model: maak inzichtelijk hoe de gegevens in de dataset met elkaar samenhangen, laat de relaties zien. Doe dit volgens het resource description framework (RDF): elk wordt beschreven aan de hand van een subject (onderwerp), predicate (eigenschap) en object (lijdend voorwerp of waarde). Zie de afbeelding hieronder:
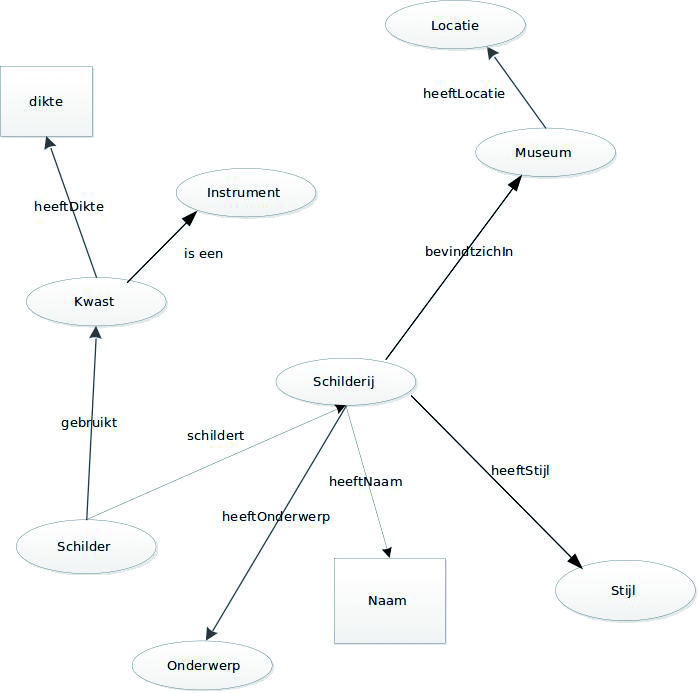 Voorbeeld van een semantisch model. (Bron: https://www.pldn.nl/wiki/Boek/Verhelst)
Voorbeeld van een semantisch model. (Bron: https://www.pldn.nl/wiki/Boek/Verhelst)
Leg het semantisch model vast in een machineleesbare taal, oftewel in tekst die verwerkt kan worden door software. Een voorbeeld hiervan is web ontology language (OWL).
- Data linkbaar maken: leg nu de data (aan de hand van het semantische model) ook vast in een machineleesbare taal.
- Licentie voor gebruik van de data toekennen: de gebruiksrechten voor de data (bv. wie heeft toegang?) worden in de volgende stap vastgelegd in de metadata, maar vanwege het belang hiervan is het bepalen van de rechten opgenomen als expliciete stap in de FAIRification.
- Metadata definiëren: de dataset is pas bruikbaar voor anderen als deze goed wordt omschreven. Lees meer hierover verderop.
- De FAIRified-data beschikbaar maken: publiceer de FAIRified-data, samen met de metadata, zodat de metadata geïndexeerd kan worden door zoekmachines en de data toegankelijk is (al dan niet na authenticatie en autorisatie).
Delen via een repository: FAIR Datapoint
In principe kunnen FAIR-datasets op allerlei manieren ontsloten worden, want het is een kwestie van een toegang geven tot de juiste bestanden (data en metadata). Maar het mooist is natuurlijk als dataverwerkingssoftware zelf datasets kan vinden en gebruiken. Dit kan door de FAIR-datasets te ontsluiten via een repository die óók weer voldoet aan de FAIR-principes. De software waarmee je data wilt bekijken of verwerken, hoeft dan enkel verbinding te maken met deze repository, de rest gaat vanzelf.
Er bestaan al diverse repositories die zijn opgezet volgens de FAIR-principes, zoals 4TU.ResearchData en DANS. Een samenwerkingsverband zou hiervan gebruik kunnen maken, vaak wel tegen betaling.
Er kan ook een eigen repository opgezet worden. Hiervoor hebben de bedenkers van de FAIR-principes een ‘basisrepository’ gemaakt die je kunt overnemen: een FAIR Datapoint (FDP). De broncode is vrij beschikbaar, zodat je hiermee je eigen FDP kunt maken. Er is ook uitgebreide documentatie beschikbaar.
Metadata
Een essentiële rol in de gegevensontwikkeling is weggelegd voor metadata: data over data. Zonder metadata hebben datasets geen betekenis voor een computer en kan software de gegevens dan ook niet op de juiste manier verwerken.
We onderscheiden drie hoofdtypen metadata:
- Administratieve metadata zijn gegevens die te maken hebben met het beheer van de datasets, bijvoorbeeld eigenaar, hoofdonderzoeker, projectmedewerkers, financier, aanmaakdatum/periode, etc.
- Beschrijvende of citatie-metadata zijn gegevens over een dataset waarmee mensen deze kunnen ontdekken en identificeren, zoals de auteurs, titel, samenvatting, trefwoorden, gerelateerde publicaties, etc.
- Structurele metadata lichten toe hoe een dataset tot stand is gekomen en hoe deze intern is gestructureerd. Structurele metadata beschrijven bijvoorbeeld de gebruikte eenheden, verzamelmethode, steekproefomvang, categorieën, variabelen, etc. Dit type metadata moet voldoen aan de afspraken die binnen het samenwerkingsverband gemaakt zijn, zie hieronder.
Metadata-templates
De kwaliteit van de metadata heeft een enorme impact op de herbruikbaarheid van data. Het is daarom belangrijk om binnen het samenwerkingsverband afspraken te maken over de metadata. Dit kan middels een metadata-template: een vaste vorm waarin alle metadata ‘gegoten’ moet worden. Er bestaan diverse generieke templates, maar die benoemen wellicht niet alle metadata die voor een specifiek samenwerkingsverband van belang zijn.
Speciaal voor samenwerkingsverbanden op het gebied van kabels en leidingen in de ondergrond, zijn er binnen het project SidO enkele metadata-templates ontwikkeld. Deze zijn vrij beschikbaar via GitHub.